Execution performance of NAS NBP 3.3
Results obtained on May, 2017.
The NAS Parallel Benchmarks (NPB) are a well-known suite of performance benchmarks to estimate possibilities of HPC systems. They were developed in NASA Numerical Aerodynamic Simulation Program and supported in NASA Advanced Supercomputing (NAS) Division. The following tests from NAS Parallel Benchmarks had been parallelized using Fortran-DVMH high-level language:
- MG (MultiGrid) – Approximation of the solution for a three-dimensional discrete Poisson equation using the V-cycle multigrid method.
- CG (Conjugate Gradient) – Approximation to the smallest eigenvalue of a large sparse symmetric positive-definite matrix using the inverse iteration method together with the conjugate gradient method as a subroutine for solving systems of linear equations.
- FT (Fast Fourier Transform) – Solution of three-dimensional partial differential equation (PDE) using the fast Fourier transform (FFT).
- EP (Embarrassingly Parallel) – Generation of independent Gaussian random variates using the Marsaglia polar method.
- BT (Block Tridiagonal), SP (Scalar Pentadiagonal) and LU (Lower-Upper) – Solution of a synthetic system of nonlinear PDEs (three-dimensional system of Navier-Stokes equations for compressible fluid or gas) using three different algorithms: block three-diagonal scheme with the method of alternating directions (BT), the scalar pentadiagonal scheme (SP) and method of symmetric successive over-relaxation (algorithm SSOR of LU).
For each problem there is a set of input data. The set is determined by the class of the test. In total, there are 7 classes: S and W classes determine very small input data and are used primarily for testing and debugging during development; A, B and C classes determine small, medium and large data respectively, that designed to test a single node; D and E classes determine very large and huge data, designed to test several nodes.
There are no data dependencies in the loops of MG, CG, FT and EP tests. But the loops of LU, BT and SP tests have regular data dependencies due to using the method of alternating directions in SP, BT and successive over relaxation method in LU.
Table 1 shows the execution times of implemented tests and the diagrams demonstrating acceleration of the tests are shown below.
- Serial versions of the original tests executed on a one core of processor Intel Xeon E5 1660 v2.
- Parallel versions of the tests written in Fortran-DVMH language, executed on the following graphics accelerators: NVIDIA Tesla C2070 with enabled ECC (Fermi generation), NVIDIA GTX Titan (Kepler generation), NVIDIA Tesla k40 with ECC disabled (Kepler generation).
- Parallel versions of the tests written in Fortran-DVMH language, executed on 6-cores processor Intel Xeon E5 1660 v2 with active Hyper Threading (2 threads per core) and disabled Turbo Boost and on 60-cores Intel Xeon Phi 5110 with active Hyper Threading (4 threads per core).
Serial versions of the programs were compiled by Intel Fortran Compiler V17.0 with options -O3 -mcmodel=medium -shared-intel. To compile Fortran-DVMH programs following compilers had been used:
- Intel Fortran Compiler V17.0 with options -O3 -no-scalar-rep -qopenmp;
- Intel C/C++ Compiler V17.0 with options -O3 -no-scalar-rep -qopenmp;
- NVidia Compiler V8.0 with options -arch=sm_35 -O3 -DCUDA_NO_SM_20_INTRINSICS.
Table 1. Execution times of NAS NPB 3.3
| Тests | Fortran | Fortran-DVMH | |||||
|---|---|---|---|---|---|---|---|
| Intel Xeon E5 1660 v2 | NVIDIA Tesla C2070 (ECC on) |
NVIDIA GTX Titan (ECC off) |
NVIDIA Tesla k40 (ECC off) |
Intel Xeon E5 1660 v2 | Intel Xeon Phi 5110 | ||
| BT | A | 40,7 | 9,61 | 2,51 | 1,65 | 7 | 8,57 |
| B | 166,9 | 46,4 | 8,06 | 5,04 | 28,8 | 25,3 | |
| C | 713,3 | 146,4 | 26,69 | 16,42 | 117,69 | 97,11 | |
| SP | A | 28,6 | 6,43 | 2,39 | 2,62 | 6,75 | 13,6 |
| B | 116,9 | 26,8 | 9,33 | 6,68 | 25,2 | 30,1 | |
| C | 483,24 | 106,3,6 | 29,3 | 31,26 | 122,25 | 116,6 | |
| LU | A | 35,07 | 5,59 | 4,04 | 3,01 | 4,7 | 18,62 |
| B | 158,5 | 16,82 | 10,58 | 7,23 | 21,8 | 57,04 | |
| C | 852,3 | 53,5 | 30,91 | 20,3 | 94,37 | 164,4 | |
| EP | A | 16,7 | 0,24 | 0,42 | 0,12 | 1,5 | 0,77 |
| B | 67,33 | 0,62 | 1,01 | 0,2 | 6,26 | 2,97 | |
| C | 266,3 | 2,64 | 3,77 | 0,9 | 25,02 | 11,67 | |
| MG | A | 1,06 | 0,23 | 0,16 | 0,16 | 0,38 | 0,54 |
| B | 4,96 | 1,02 | 0,69 | 0,77 | 1,87 | 2,7 | |
| C | 42,3 | 6,24 | 3,66 | 3,56 | 15,96 | 20,65 | |
| CG | A | 0,94 | 1,84 | 0,59 | 0,94 | 0,31 | 1,41 |
| B | 78,8 | 55,14 | 19,47 | 36,87 | 15,3 | 20,69 | |
| C | 221 | 164,88 | 60,1 | 110,03 | 40,8 | 64,4 | |
| FT | A | 3,05 | 0,67 | 0,25 | 0,28 | 0,45 | 0,63 |
| B | 39,5 | 9,35 | 3,64 | 4,14 | 6,38 | 8,41 | |
| C | 199,3 | 41,79 | 15,7 | 18 | 25,7 | 33,6 | |
The diagrams demonstrating acceleration of NAS NPB 3.3
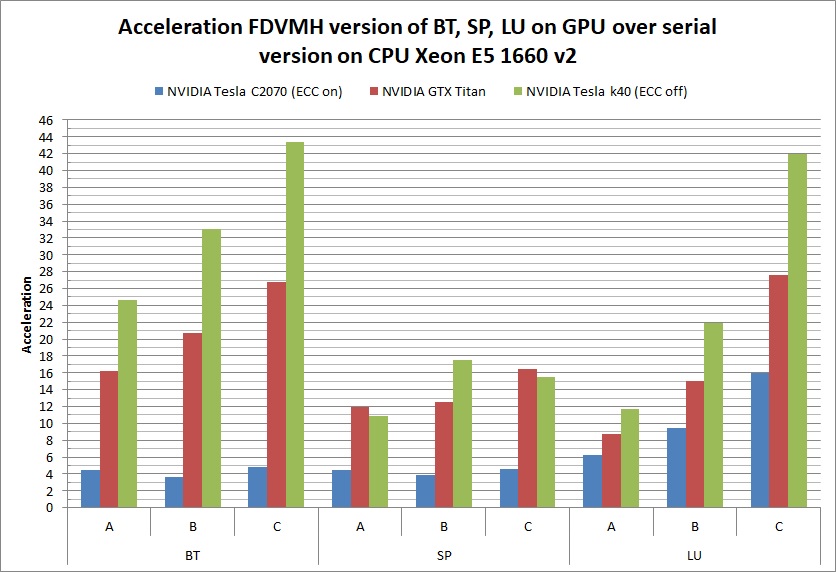
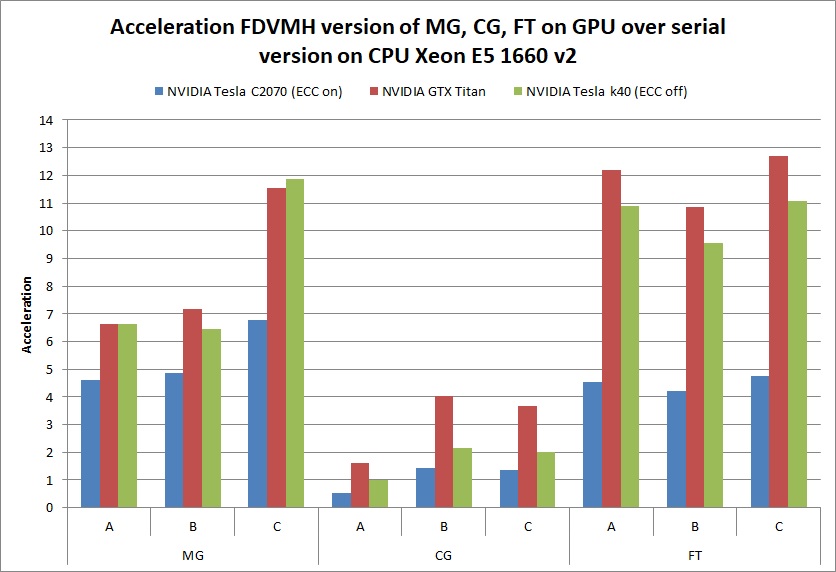
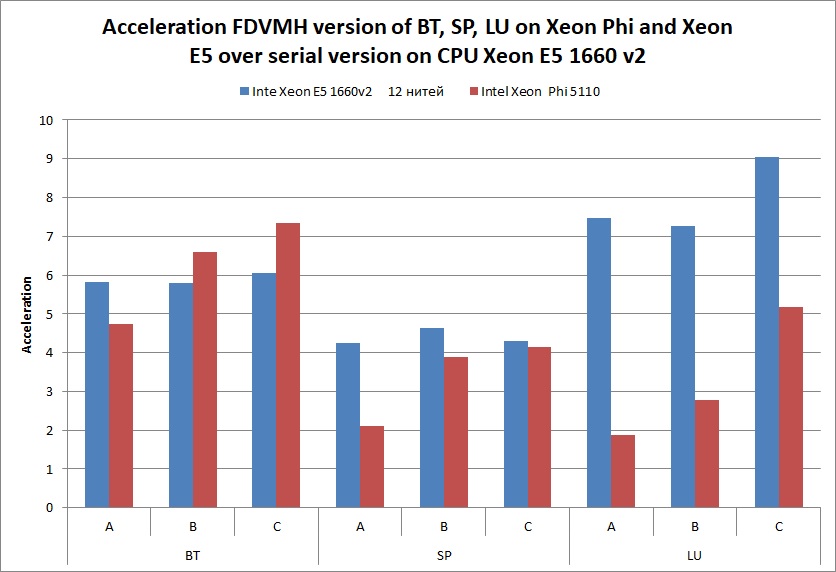
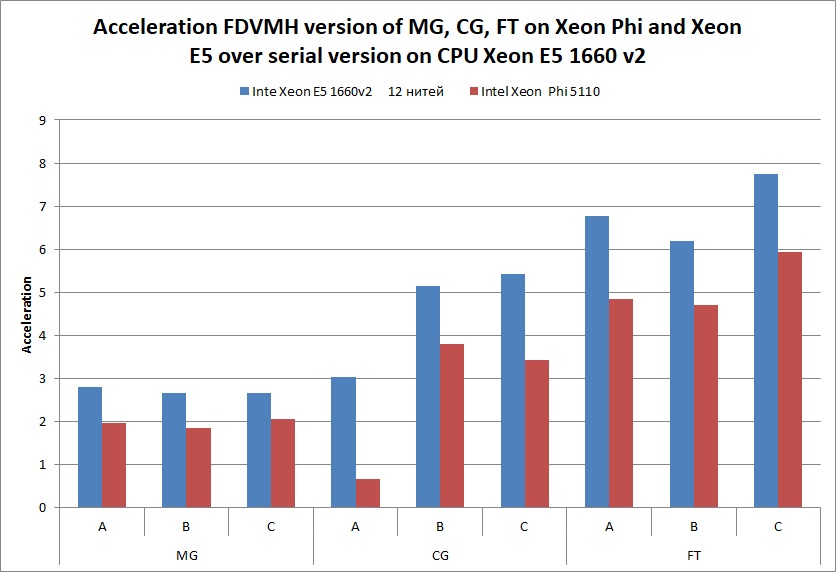
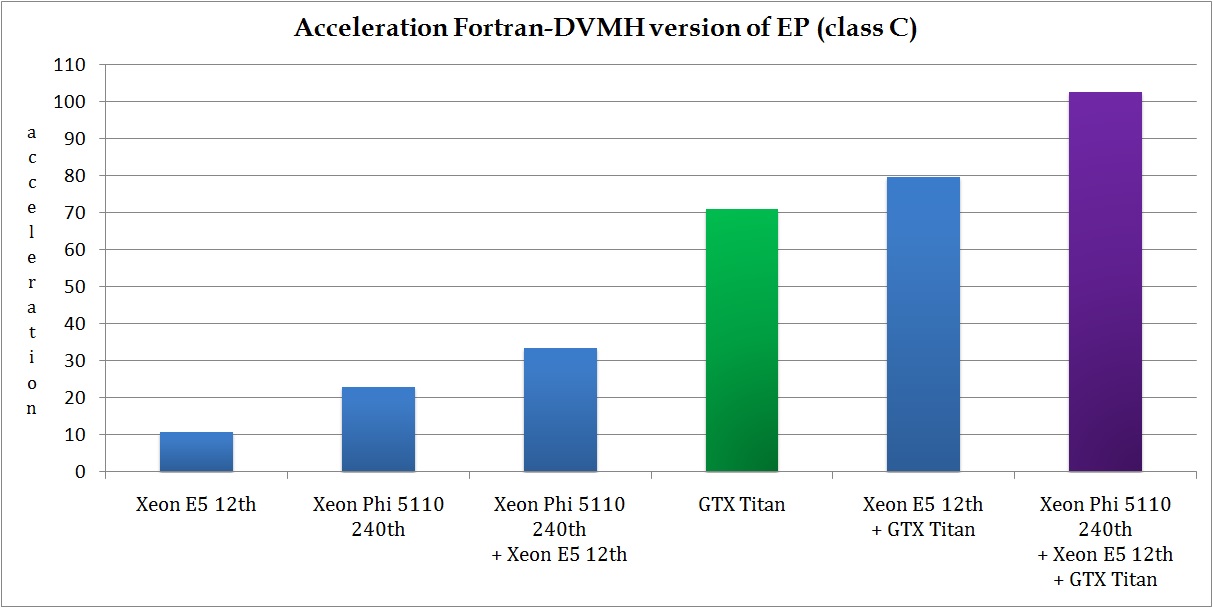
Fig. 5 shows the acceleration of EP test on class C compared to a sequential version of the program executed on a single core of Intel Xeon E5 1660 v2. This test was executed on different architectures separately as well as in the following combinations: Intel Xeon E5 1660 v2 + GTX Titan, Intel Xeon E5 1660 v2 + Intel Xeon Phi and Intel Xeon E5 1660 v2 + GTX Titan + Intel Xeon Phi. Purple color show case when load balancing was additionally used by setting the ratio of the weights of all cores of CPU and GPU, and ratio of weights of MPI-processes mapped on the CPU and coprocessor.
Comparison of FDVMH versions of the tests from NAS NBP 3.3 package with the following versions of the programs was done in May, 2015:
- with source versions of NAS tests parallelized using OpenMP,
- with C versions of NAS tests parallelized using OpenCL,
- with C++ versions of NAS tests parallelized using CUDA (only LU, BT, SP tests).