Эффективность выполнения тестов NAS NPB 3.3
Результаты получены в Марте 2015 г.
C помощью языка Fortran-DVMH были распараллелены тесты производительности из пакета NAS Parallel Benchmarks, нацеленные на проверку возможностей высокопараллельных суперкомпьютеров. Они были разработаны в рамках программы NASA Numerical Aerodynamic Simulation Program и поддерживаются в NASA Advanced Supercomputing (NAS) Division. Были распараллелены следующие тесты:
- MG (MultiGrid) — Аппроксимация решения трехмерного дискретного уравнения Пуассона при помощи V-циклового многосеточного метода.
- CG (Conjugate Gradient) – Приближение к наименьшему собственному значению большой разреженной симметричной положительно определенной матрицы с использованием метода обратной итерации вместе с методом сопряженных градиентов в качестве подпрограммы для решения СЛАУ.
- FT (Fast Fourier Transform) – Решение трехмерного уравнения в частных производных при помощи Быстрого преобразования Фурье (FFT).
- EP (Embarrassingly Parallel) – Генерация независимых нормально распределенных случайных величин при помощи Marsaglia polar метода.
- BT (Block Tridiagonal), SP (Scalar Pentadiagonal) и LU (Lower-Upper) – Решают синтетическую систему нелинейных дифференциальных уравнений в частных производных (3-х мерная система уравнений Навье-Стокса для сжимаемой жидкости или газа), используя три алгоритма: блочная трехдиагональная схема с методом переменных направлений (BT), скалярная пятидиагональная схема (SP) и метод симметричной последовательной верхней релаксации (алгоритм SSOR, задача LU).
Для каждой задачи существует набор входных данных. Данный набор определяется классом теста. Всего существует 7 классов: S и W – задают очень маленькие входные данные, используются в основном для тестирования и отладки во время разработки; A, B, и С – задают маленькие, средние и большие входные данные, которые предназначены для тестирования одного узла; D и E – задают очень большие и огромные входные данные, которые предназначены для тестирования нескольких узлов.
В циклах тестов MG, CG, FT, EP нет зависимостей по данным. В циклах тестов LU, BT, SP присутствуют регулярные зависимости по данным, так как в основном алгоритме используется метод попеременных направлений (BT, SP) и метод последовательной верхней релаксации (LU).
В Таблице 1 представлены времена выполнения реализованных тестов, а ниже приведены графики, демонстрирующие ускорения тестов:
- Последовательные версии исходных тестов, выполненных на одном ядре процессора Intel Xeon E5 1660 v2.
- Параллельные версии тестов, написанные на языке Fortran-DVMH, выполненные на следующих графических ускорителях: NVIDIA Tesla C2050 с включенным ECC (поколения Fermi), NVIDIA GTX Titan (поколения Kepler), NVIDIA Tesla k20 с включенным ECC (поколения Kepler).
- Параллельные версии тестов, написанные на языке Fortran-DVMH, выполненные на 6-ти ядерном процессоре Intel Xeon E5 1660 v2 с включенным Hyper Threading (2 потока на ядро) и отключенным Turbo Boost и на 60-ти ядерном Intel Xeon Phi 5110 с активным Hyper Threading (4 потока на ядро).
Последовательные версии программ были скомпилированы с помощью Intel Fortran Compiler V15.0 c опциями -O3 -mcmodel=medium -shared-intel. Для компиляции Fortran-DVMH программ использовались:
- Intel Fortran Compiler V15.0 с опциями -O3 -no-scalar-rep -qopenmp;
- Intel C/C++ Compiler V15.0 с опциями -O3 -no-scalar-rep -qopenmp;
- NVIDIA Compiler V6.5 с опциями -arch=sm_35 -O3 -DCUDA_NO_SM_20_INTRINSICS.
Таблица 1. Времена выполнения тестов NAS NPB 3.3
| Тесты | Fortran | Fortran-DVMH | |||||
|---|---|---|---|---|---|---|---|
| Intel Xeon E5 | NVIDIA Tesla C2050 (c ECC) |
NVIDIA GTX Titan (без ECC) |
NVIDIA Tesla k20 (c ECC) |
Intel Xeon E5 | Intel Xeon Phi 5110 | ||
| BT | A | 40,7 | 9,61 | 2,71 | 2,78 | 6,97 | 7,68 |
| B | 166,9 | 46 | 8,67 | 8,31 | 28,8 | 20,9 | |
| C | 713,3 | 142,7 | 28,9 | 28,15 | 118,1 | 74 | |
| SP | A | 28,6 | 7,4 | 2,25 | 3,25 | 6,75 | 11,6 |
| B | 116,9 | 26,12 | 9,65 | 13,34 | 29,18 | 27 | |
| C | 483,24 | 92,6 | 29,74 | 45,9 | 122,2 | 120 | |
| LU | A | 35,07 | 7,15 | 4,76 | 4,74 | 4,7 | 16,5 |
| B | 148,5 | 20,4 | 11,84 | 10,09 | 33,7 | 57,7 | |
| C | 852,3 | 61,5 | 33,73 | 29,91 | 99 | 157,3 | |
| EP | A | 16,7 | 0,28 | 0,41 | 0,17 | 1,5 | 0,78 |
| B | 67,33 | 0,71 | 1,02 | 0,27 | 5,99 | 2,99 | |
| C | 266,3 | 2,6 | 3,9 | 1,13 | 23,96 | 11,6 | |
| MG | A | 1,06 | 0,46 | 0,19 | 0,38 | 0,38 | 0,61 |
| B | 4,96 | 2,17 | 0,87 | 1,86 | 2,14 | 2,8 | |
| C | 42,3 | 8,33 | 3,89 | 5,78 | 16,2 | 15,5 | |
| CG | A | 0,94 | 2,14 | 0,56 | 1,42 | 0,31 | 1,41 |
| B | 78,8 | 71,7 | 19,2 | 35,22 | 15,3 | 21,18 | |
| C | 221 | 221,7 | 59,16 | 102,9 | 40,8 | 64,6 | |
| FT | A | 3,05 | 0,75 | 0,31 | 0,47 | 0,45 | 0,64 |
| B | 39,5 | 10,7 | 3,9 | 6,63 | 6,38 | 8,46 | |
| C | 199,3 | 50,8 | 18,4 | 31,42 | 25,7 | 46,6 | |
Графики, демонстрирующие ускорения тестов NAS NPB 3.3
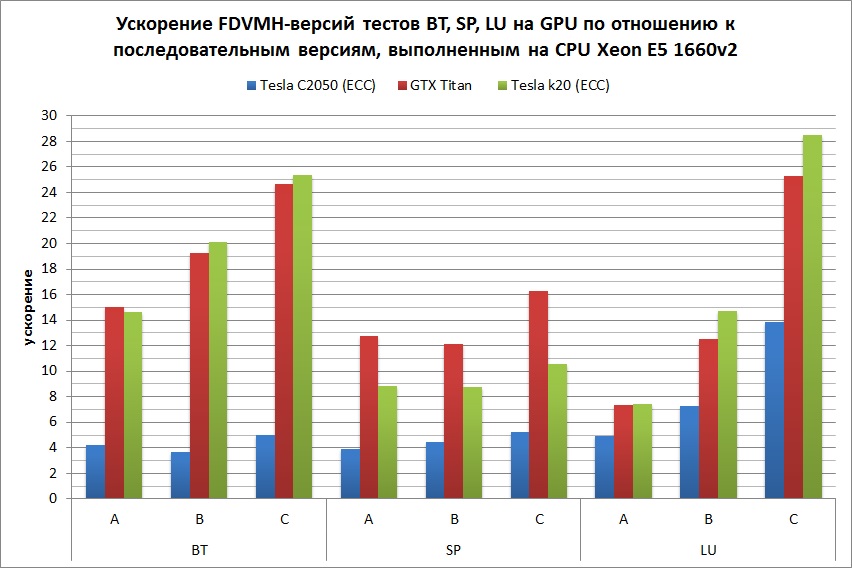
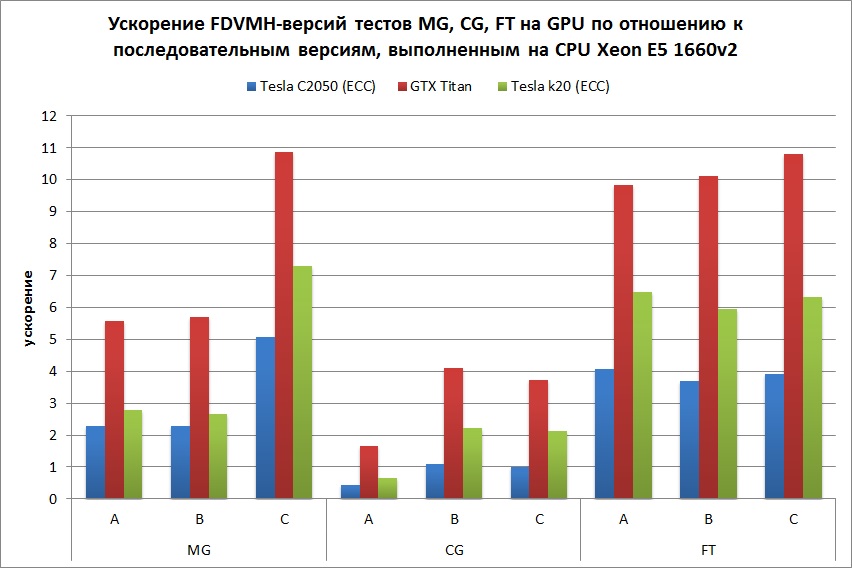
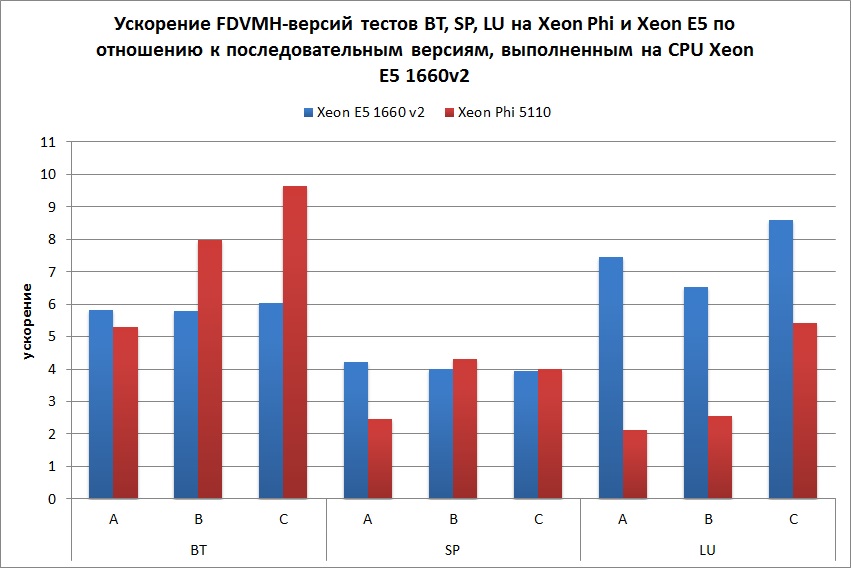
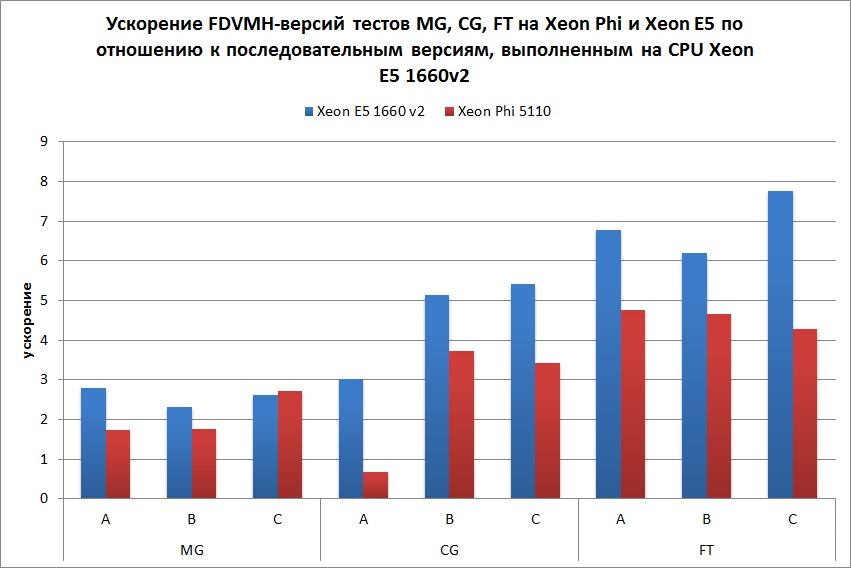
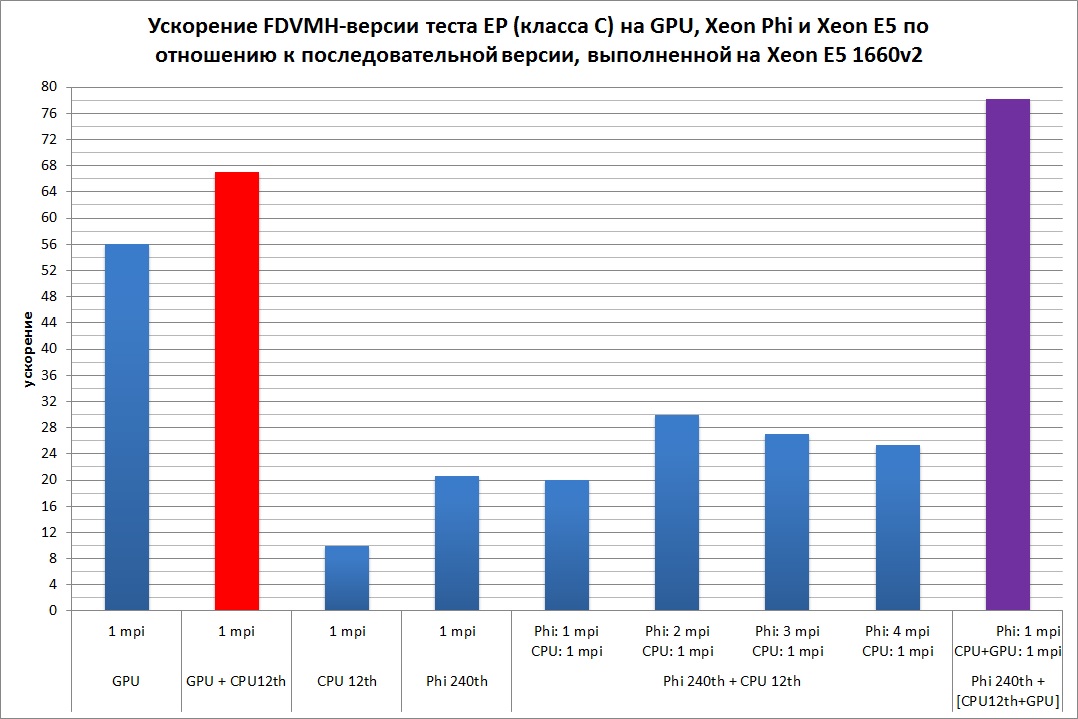
На Рис. 5 показано ускорение теста EP на классе С по сравнению с последовательной версией данной программы, выполненной на одном ядре Intel Xeon E5 1660 v2. Данный тест выполнялся на разных архитектурах по отдельности, а также в следующих комбинациях: Intel Xeon E5 1660 v2 + GTX Titan, Intel Xeon E5 1660 v2 + Intel Xeon Phi и Intel Xeon E5 1660 v2 + GTX Titan + Intel Xeon Phi. Для каждой конфигурации запуска указывается количество MPI-процессов и количество OpenMP-нитей внутри каждого из процессов. Красным и сиреневым цветом показаны случаи, когда дополнительно использовалась балансировка нагрузки путем задания соотношения весов всех ядер центрального и графического процессоров и соотношения весов MPI-процессов, отображаемых на центральный процессор и сопроцессор.
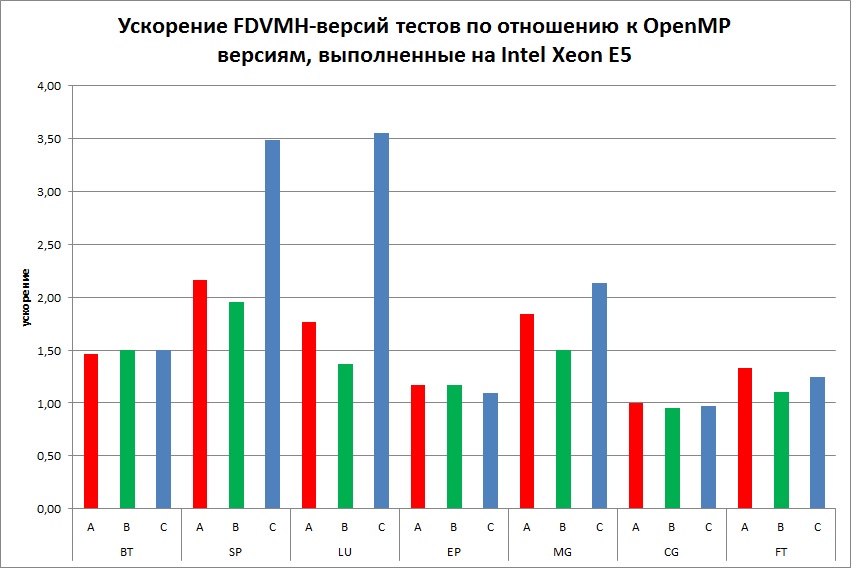
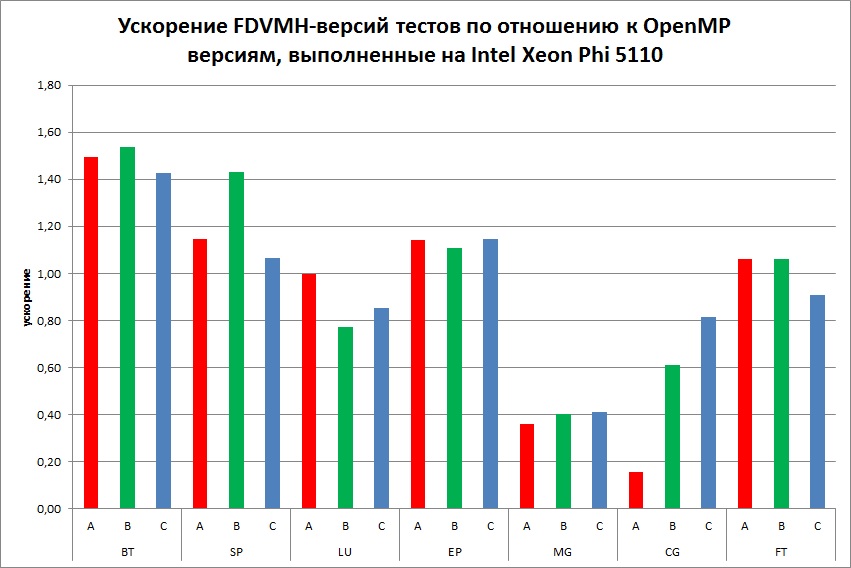
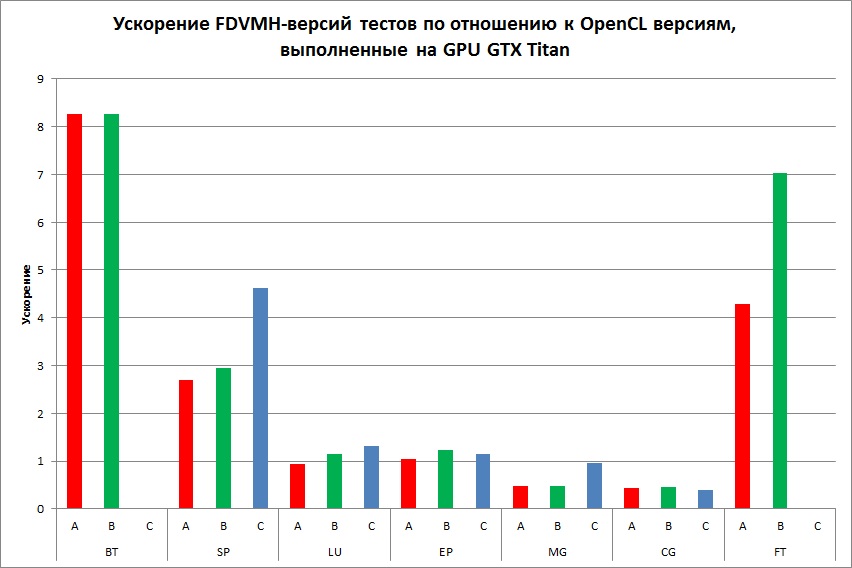
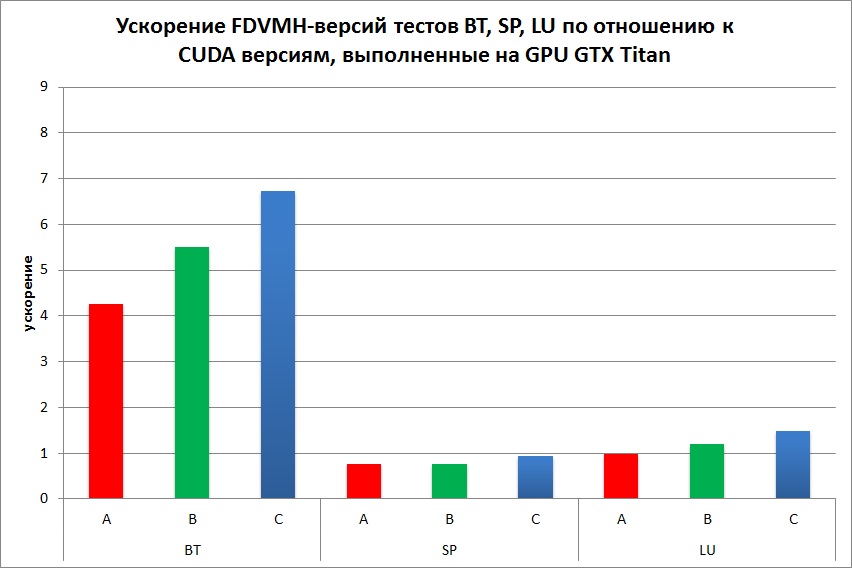
Ниже приведено сравнение FDVMH-версий тестов из пакета NAS NBP 3.3 со следующими вариантами программ:
- с исходными версиями тестов NAS, распараллеленными с помощью OpenMP (Рис. 6, Рис. 7);
- с версиями тестов NAS, написанными на языке Си и распараллеленными на OpenCL (Рис. 8);
- с версиями тестов NAS, написанными на языке Си++ и распараллеленными на CUDA (только тесты LU, BT, SP) (Рис. 9).
Для компиляции программ использовались NVIDIA CUDA Toolkit V6.5, PGI V15.0, Intel Fortran V15.0. По сравнению с OpenMP версиями стандартных тестов, выполненных на ЦПУ, DVMH версии не уступают по производительности, а на некоторых тестах (SP, LU) выигрывают в 3,5 раза. Эти же тесты, выполненные на Intel Xeon Phi, показывают примерно такое же ускорение, как и DVMH-версии, кроме тестов MG и CG (замедление примерно в 2 раза). По сравнению с OpenCL версиями, выполненными на GPU GTX Titan, DVMH версии не уступают по производительности на тестах LU и EP, в два раза замедляются на тестах MG и CG, и в 6-8 раз быстрее на тестах BT, SP и FT. Стоит также отметить, что для тестов BT и FT класса С OpenCL-версиям не хватило 6 ГБ памяти GPU, поэтому не удалось сравнить производительность на данном классе. Замедление на тестах MG и CG связано с тем, что DVMH компилятор хорошо распараллеливает программы, использующие регулярные сетки. Но в тесте MG используются разного размера сетки, а в CG – разреженные матрицы. Запуски OpenCL программ на CPU и Xeon Phi показали очень плохие результаты, поэтому они не отражены в данном разделе. По сравнению с CUDA версиями, выполненными на GPU GTX Titan, DVMH версии не уступают по производительности на тестах LU и SP, и в 4-7 раз быстрее на тесте BT.