Эффективность выполнения тестов NAS NPB 3.3
Результаты получены в Январе 2020 г.
C помощью системы автоматизированного распараллеливания SAPFOR были распараллелены тесты производительности из пакета NAS Parallel Benchmarks, нацеленные на проверку возможностей высокопараллельных суперкомпьютеров. Было выполнено распараллеливание последовательных версий тестов, написанных на языке Си [1]. Тесты были разработаны в рамках программы NASA Numerical Aerodynamic Simulation Program и поддерживаются в NASA Advanced Supercomputing (NAS) Division. Было выполнено автоматизированное распараллеливание следующих тестов:
- CG (Conjugate Gradient) – Приближение к наименьшему собственному значению большой разреженной симметричной положительно определенной матрицы с использованием метода обратной итерации вместе с методом сопряженных градиентов в качестве подпрограммы для решения СЛАУ.
- EP (Embarrassingly Parallel) – Генерация независимых нормально распределенных случайных величин при помощи Marsaglia polar метода.
- BT (Block Tridiagonal) и LU (Lower-Upper) – Решают синтетическую систему нелинейных дифференциальных уравнений в частных производных (3-х мерная система уравнений Навье-Стокса для сжимаемой жидкости или газа), используя два алгоритма: блочная трехдиагональная схема с методом переменных направлений (BT) и метод симметричной последовательной верхней релаксации (алгоритм SSOR, задача LU).
Для каждой задачи существует набор входных данных. Данный набор определяется классом теста. Всего существует 7 классов: S и W – задают очень маленькие входные данные, используются в основном для тестирования и отладки во время разработки; A, B, и С – задают маленькие, средние и большие входные данные, которые предназначены для тестирования одного узла; D и E – задают очень большие и огромные входные данные, которые предназначены для тестирования нескольких узлов.
В циклах тестов CG, EP нет зависимостей по данным. В циклах тестов LU, BT присутствуют регулярные зависимости по данным, так как в основном алгоритме используется метод попеременных направлений (BT) и метод последовательной верхней релаксации (LU), который образует зависимость по трем измерениями массива.
В процессе распараллеливание под руководством пользователя с помощью системы SAPFOR тесты были приведены к потенциально параллельному виду, для которого возможно автоматическое распараллеливания с помощью автоматически распараллеливающего компилятора входящего в состав системы SAPFOR.
В Таблице 1 представлены времена выполнения распараллеленных тестов:
- Последовательные версии исходных тестов, выполненных на одном ядре процессора Intel Xeon E5 1660 v2.
- Параллельные версии тестов, написанные на языке Fortran-DVMH, выполненные на NVIDIA GTX Titan (поколения Kepler).
- Параллельные версии тестов, написанные на языке Fortran-DVMH, выполненные на 6-ти ядерном процессоре Intel Xeon E5 1660 v2 с включенным Hyper Threading (2 потока на ядро) и отключенным Turbo Boost.
Последовательные версии программ были скомпилированы с помощью Intel Fortran Compiler V19.0 c опциями -O3 -mcmodel=medium -shared-intel. Для компиляции СDVMH программ использовались:
- Intel Fortran Compiler V19.0 с опциями -O3 -no-scalar-rep -qopenmp;
- Intel C/C++ Compiler V19.0 с опциями -O3 -no-scalar-rep -qopenmp;
- NVIDIA Compiler V8.0 с опциями -arch=sm_35 -O3 -DCUDA_NO_SM_20_INTRINSICS.
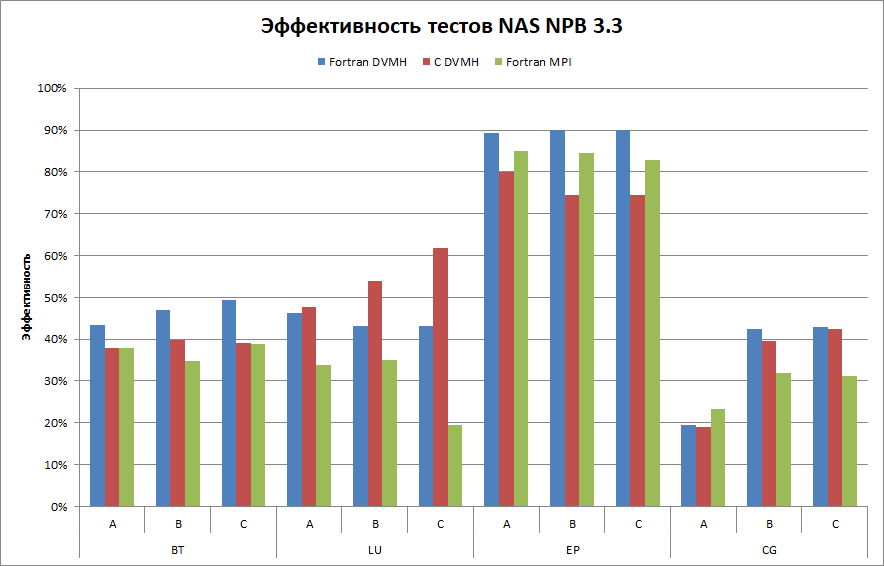
В связи с отсутствием MPI-версий для программ, написанных на языке C, для сравнения приведены времена запусков версий программ на Fortran DVMH, написанных вручную и времена MPI-версий от разработчиков пакета программ. Последовательные C версии близки к оригинальным Фортран-версиям программ, времена последовательного выполнения также близки. Есть небольшое преимущество в выполнении последовательных С версий, которое связано, скорее, с особенностями реализации компиляторов с языка Си, чем с отличиями между исходными кодами версий. Это позволяет говорить о возможности сравнения ускорений получаемых для Фортран и Си версий программ между собой. На Рис. 1 приведено сравнение эффективности выполнения тестов распараллеленных с помощью MPI (Fortran), Fortran-DVMH и C-DVMH. Стоит отметить, что запуск MPI-версий тестов возможен только на определенных конфигурациях, в отличие от DVMH-версий, которые могут быть запущены на всех имеющихся ресурсах. При указании времени выполнения MPI-версий тестов в скобках также указана конфигурация запуска.
Таблица 1. Времена выполнения тестов NAS NPB 3.3
| Тесты | Fortran | C | Fortran-DVMH | Fortran-MPI | C-DVMH (SAPFOR) | |||
|---|---|---|---|---|---|---|---|---|
| Intel Xeon E5 1660 v2 | NVIDIA GTX Titan (без ECC) |
Intel Xeon E5 1660 v2 | Intel Xeon E5 1660 v2 (конфигурация) | NVIDIA GTX Titan (без ECC) |
Intel Xeon E5 1660 v2 | |||
| BT | A | 37,61 | 39,71 | 2,59 | 7,23 | 11,03 (n=9) | 18,17 | 8,73 |
| B | 157,3 | 169,72 | 8,35 | 27,89 | 50,32 (n=9) | 51,42 | 35,62 | |
| C | 679,18 | 720,86 | 27,63 | 114,43 | 194,13 (n=9) | 159,49 | 153,71 | |
| LU | A | 27,91 | 29,02 | 4,02 | 5,03 | 6,86 (n=12) | 5,68 | 5,07 |
| B | 119,46 | 121,8 | 11,18 | 23,06 | 28,35 (n=12) | 15,29 | 18,79 | |
| C | 522,22 | 552,39 | 33,29 | 100,98 | 222,34 (n=12) | 51,09 | 74,47 | |
| EP | A | 15,97 | 15,83 | 0,43 | 1,49 | 2,35 (n=8) | 0,46 | 1,65 |
| B | 63,94 | 63,2 | 1,04 | 5,92 | 9,45 (n=8) | 1,3 | 7,08 | |
| C | 255,75 | 252,94 | 3,89 | 23,68 | 35,58 (n=8) | 4,26 | 28,3 | |
| CG | A | 0,84 | 0,82 | 0,66 | 0,36 | 0,3 (n=12) | 0,71 | 0,36 |
| B | 78,16 | 75,99 | 22,95 | 15,39 | 20,37 (n=12) | 14,69 | 15,96 | |
| C | 210,23 | 213,11 | 66,59 | 40,89 | 56,2 (n=12) | 44,25 | 41,81 | |
[1] Seo, S., Jo, G., Lee, J.: Performance Characterization of the NAS Parallel Benchmarks in OpenCL. In: 2011 IEEE International Symposium on. Workload Characterization (IISWC), pp. 137-148. (2011)